
Build Isolation in Apache Kafka
Waiting in line. Noisy neighbors. No thanks!

In the last post, I mentioned some of the problems with our Jenkins environment. General instability leading to failed builds was the most severe problem, but long queue times and issues with noisy neighbors were also major pain points.
GitHub Actions has effectively eliminated these issues for Apache Kafka.
Jenkins Troubles
Waiting in line. Queuing up. An inescapable fact of life. Until recently, it was also an all-too-common reality for Apache Kafka builds.
The traditional Jenkins deployment architecture uses the controller/worker pattern (called master/slave by Jenkins). This architecture uses a single Jenkins controller instance to monitor the worker nodes and schedule jobs. The nodes can be physical servers, virtual machines, compute instances in the cloud, or (more recently) virtualized containers. Anything that can run the Jenkins agent can be a worker.
The Jenkins system managed by the (wonderful) ASF Infra team consists of a shared Jenkins controller and a fairly large pool of workers. These workers are always active regardless of the demand for build capacity. If the projects are idle (like they are on weekends), then there is low utilization of the workers. If the projects are busy (like they are on Mondays during working hours), then the workers become saturated and a queue starts to form.
A standby worker architecture like this invariably creates a conflict between cost and build queue times. Sizing the worker pool for peak demand will reduce the average queue times, but it will be horribly cost inefficient.
Another side-effect of this Jenkins architecture is that your build might be running on a worker node that is already busy with another build. After all, servers tend to have a lot of cores and memory, so why not allow them to take on multiple jobs at once?
Since the Jenkins agent is just a Java process, it does not really get any guarantees from the operation system regarding the underlying resources. If an agent can execute more than one build concurrently, then there is potential for bad interactions between the builds.
This is known as the "noisy neighbor" problem, and historically it was very prevalent in Kafka builds. Turns out, more often than not, the noisy neighbor we were dealing with was Kafka itself! The Kafka test suite has grown to over 30,000 test cases (at both unit and integration levels). To achieve “reasonable” build times, we also employ a high number of parallel test threads. This puts a lot of stress on the Jenkins worker. Doubly so if that work is unlucky enough to be running two Kafka builds.
Sad Developers
The day-to-day reality that Kafka developers had deal with was long queue times due to an under-sized resource pool and instability due to noisy neighbors (including ourselves). We desparately needed isolation in our CI environment. One common answer to this problem is containerization with on-demand worker allocation.
While it is possible to set up Jenkins agents to run in Docker containers and to schedule resources on demand, it is not exactly common. Like many modern CI features, the container support in Jenkins feels like a tacked-on afterthought. This same criticism goes for things like the UI and the declarative pipeline definitions. They’re just not quite there.
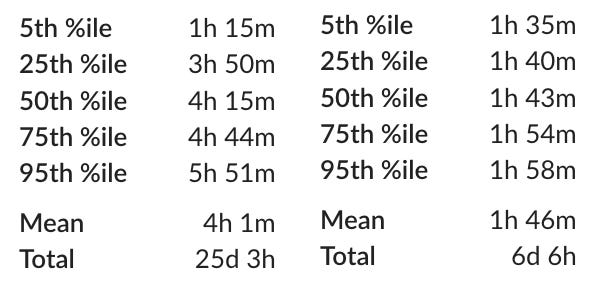
We took a data-driven approach to this build overhaul and an early metric we were focused on was the variability of the build times. Specifically, I was interested in the interquartile range (IQR) of build times. IQR is the difference between the 75th and 25th percentiles and is a pretty useful qualitative metric when talking about a distribution.
During the month of August last year (2024), the IQR for our Jenkins trunk builds was 53 minutes. This meant that on average you had about a one hour variability in the build time just due to environmental factors. Not only is this really bad from a technical perspective, but also a social and community perspective.
I cannot overstate how frustrating and even demoralizing it was to wait for hours and hours on a build with no idea when it would be completed. Maybe you would get lucky and it would only take two hours. Maybe it would take six. You really just had no clue.
Isolation Matters
Build isolation is one area where GitHub Actions really shines. All workflows are run in a container with very reliable resource isolation. We can see just how good the isolation is by comparing the IQR for build times between GitHub Actions and Jenkins.
When we started running the build in parallel GitHub Actions, we noticed something incredible. The interquartile range had reduced to 14 minutes! The improvement was even more drastic when looking at the 5th and 95th percentiles. Honestly, I was very skeptical of the results at first. It seemed too good to be true. After a few weeks, we collected sufficient data to be confident that these results were valid.
Simply moving from Jenkins to GitHub Actions reduced the variability of build times by an order of magnitude.
Not only did our build times become more stable, but our mean build time was also drastically reduced. The GitHub Actions workers have far fewer resources (cores and memory) than the Jenkins workers. We can see this in the data — the fastest Jenkins times (5th percentile) are quite a bit faster than the fastest GitHub Actions times. However, because of the better isolation in GitHub Actions, the variability of build times is drastically reduced, so the mean build time is far better.
In other words, isolation is important!
Switching from Jenkins to GitHub Actions has been a breath of fresh air for the project. It solved many long-standing technical problems and, from my perspective, significantly increased developer productivity. For me personally, the most impactful thing has been the consistent, repeatable build results that have allowed us to gain confidence in the build itself.
Now that we had established GitHub Actions as our CI enviornment, we could start doing all sorts of fun and interesting things in the build. More on that in future posts.